二手车价格预测-03-建模调参
创建时间:
阅读:
官方直播总结
改变精度降低内存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| def reduce_mem_usage(df):
""" iterate through all the columns of a dataframe and modify the data type
to reduce memory usage.
"""
start_mem = df.memory_usage().sum()
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum()
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
|
学习曲线
要做一个variance和bias的trade-off
training score曲线和Cross-validation score曲线间的距离象征了variance的大小
之前特征工程的遗漏的部分
对于预测值(即训练集数据的标签,这次是price)的正态化处理
主要有对数变换 指数变换 约翰逊变换
XGBoost和LightGBM学习
两种模型的基础:GBDT
GBDT(Gradient Boosting Decision Tree)
梯度提升
$$
f_t(x)=f_{t−1}(x)+h_t(x))
$$
每轮在上一轮生成的强学习器$f_{t−1}(x)xyz$基础上增加一个弱学习器$h_t(x)$,最小化本轮的损失值
用损失函数Lost function的负梯度来近似本轮的损失值
决策树
优点:灵活,解释性好
缺点:容易过拟合
XGBoost介绍及学习
直接使用
先导入一些需要的库
1
2
3
4
5
6
7
8
9
10
| import pandas
import numpy
import xgboost
from sklearn import model_selection
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
%matplotlib inline
|
处理通常的分类问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| data = pandas.read_csv('iris.data', header=None)
dataset = data.values
X = dataset[:,0:4]
Y = dataset[:,4]
label_encoder = LabelEncoder()
label_encoder = label_encoder.fit(Y)
label_encoded_y = label_encoder.transform(Y)
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = model_selection.train_test_split( X, label_encoded_y , test_size=test_size , random_state=seed )
model = xgboost.XGBClassifier()
model.fit(X_train, y_train)
print(model)
|
1
2
3
4
5
6
7
8
|
y_pred = model.predict(X_test)
print(y_pred[::5])
predictions = [round(value) for value in y_pred]
print(predictions[::5])
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
|
1
2
3
4
|
from xgboost import plot_importance
plot_importance(model)
plt.show()
|
有类别型特征时
因为XGBoost不能直接处理类别型特征,给类别性特征做One-hot encoder
1
2
3
4
5
6
7
8
9
10
11
12
13
| from sklearn.preprocessing import OneHotEncoder
encoded_x = None
for i in range(0, X.shape[1]):
label_encoder = LabelEncoder()
feature = label_encoder.fit_transform(X[:,i])
feature = feature.reshape(X.shape[0], 1)
onehot_encoder = OneHotEncoder(sparse=False, categories='auto')
feature = onehot_encoder.fit_transform(feature)
if encoded_x is None:
encoded_x = feature
else:
encoded_x = numpy.concatenate((encoded_x, feature), axis=1)
|
缺失值过多时
特征选择
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
from numpy import sort
from sklearn.feature_selection import SelectFromModel
print("model.feature_importances_", model.feature_importances_)
print("majority classifier",1 - numpy.mean(y_test))
sort_idx = numpy.argsort(-model.feature_importances_)
best_feature = sort_idx[0]
X_train_build = X_train[:,best_feature].reshape(X_train.shape[0], 1)
X_test_build = X_test[:,best_feature].reshape(X_test.shape[0], 1)
for idx in list(sort_idx):
if idx != best_feature:
X_train_build = numpy.concatenate((X_train_build,
X_train[:,idx].reshape(X_train.shape[0], 1)),
axis=1)
X_test_build = numpy.concatenate((X_test_build,
X_test[:,idx].reshape(X_test.shape[0], 1)),
axis=1)
selection_model = xgboost.XGBClassifier()
selection_model.fit(X_train_build, y_train)
y_pred = selection_model.predict(X_test_build)
predictions = [round(value) for value in y_pred]
accuracy = accuracy_score(y_test, predictions)
print("num_features=%d, Accuracy: %.2f%%" % ( X_train_build.shape[1],accuracy*100.0))
|
模型参数
我现在不太清除该先特征选择还是先调参
参考https://xgboost.readthedocs.io/en/latest/parameter.html
主要用GridSearch
1
| from sklearn.grid_search import GridSearchCV
|
1
2
3
4
5
6
7
8
9
10
| cv_params = {'subsample': [0.6, 0.7, 0.8, 0.9], 'colsample_bytree': [0.6, 0.7, 0.8, 0.9]}
other_params = {'learning_rate': 0.1, 'n_estimators':4, 'max_depth': 4, 'min_child_weight':1, 'seed': 0,'subsample': 0.8 , 'colsample_bytree': 0.8, 'gamma': 0.1, 'reg_alpha': 0, 'reg_lambda': 1}
model = xgb.XGBClassifier(**other_params)
optimized_GBM = GridSearchCV(estimator=model, param_grid=cv_params, scoring='accuracy', cv=5, verbose=1, n_jobs=4)
optimized_GBM.fit(train_x, train_y)
evalute_result = optimized_GBM.grid_scores_
print('参数的最佳取值:{0}'.format(optimized_GBM.best_params_))
print('最佳模型得分:{0}'.format(optimized_GBM.best_score_))
|
XGBoost和LightGBM区别
整理自这个直播材料
结构区别:在连续变量的划分上
确定划分点的时候最原始、最‘笨’的方法是每个点都试一次,和其他点比,复杂度O(n^2)
- 处理连续变量时,划分点的算法不同
XGboost使用的是pre-sorted base algorithms
排序后再计算,减少了比较的过程
进一步可以用直方图,拿每个区间的中位线来比较(牺牲了准确度)
LightGBM使用的是histogram based algorithms
先做了数据分桶,把连续型数据离散化
LightGBM还使用了一种技术GOSS(Gradient-based One-side Sampling)
对于gradients较小,即不那么重要的数据(这里重要度由梯度决定),只抽样部分出来
- 树的生长方式不同
- 处理离散变量
- XGBoost不能直接处理类别型变量,要先做label encoding
- LightGBM有自己的不同于传统的处理方法,更智能
参数区别
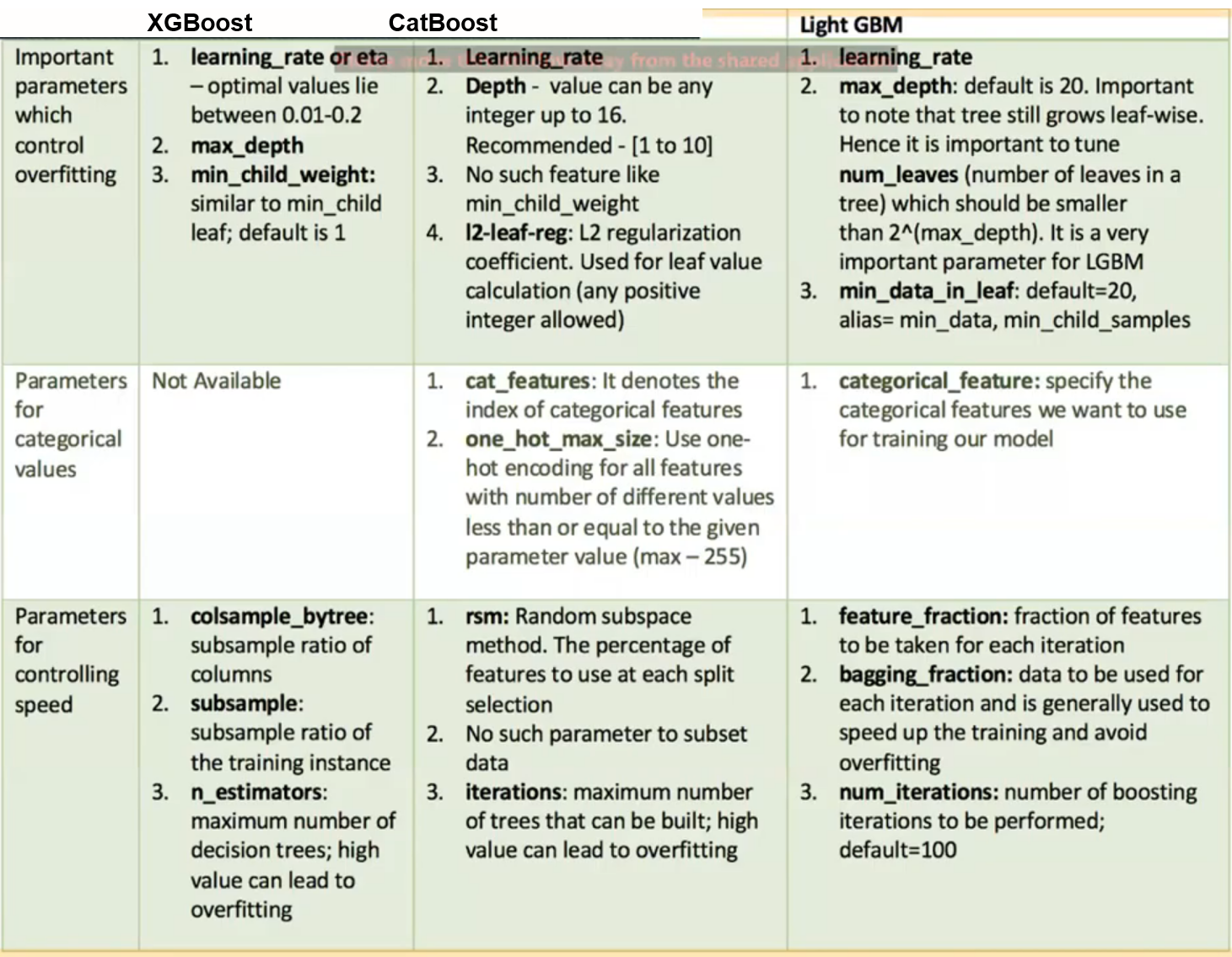
图片来自https://www.youtube.com/watch?v=dOwKbwQ97tI
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 carlos@sjtu.edu.cn

